Difference between revisions of "Apache Zeppelin"
| Line 64: | Line 64: | ||
=== Installation === |
=== Installation === |
||
| − | Télécharger le dernier binaire: https://zeppelin.incubator.apache.org/download.html |
+ | Télécharger le dernier binaire: [https://zeppelin.incubator.apache.org/download.html] |
Décompresser le tgz puis se déplacer dans le dossier. |
Décompresser le tgz puis se déplacer dans le dossier. |
||
| Line 72: | Line 72: | ||
bin/zeppelin-daemon.sh start |
bin/zeppelin-daemon.sh start |
||
| − | Si tout s'est bien passé, il suffit d'ensuite visiter http://localhost:8080 dans le navigateur. |
+ | Si tout s'est bien passé, il suffit d'ensuite visiter [http://localhost:8080] dans le navigateur. |
Revision as of 13:56, 2 April 2016
Apache Zeppelin (incubating)
Synthèse
Apache Zeppelin est projet Apache sous licence open-source Apache2. Il est actuellement en incubation. Pour rappel, l'incubateur Apache est une passerelle de validation pour tout logiciel libre susceptible de devenir un projet à part entière de la fondation Apache
Le projet fournit une interface web (notebook) qui permet d'analyser et mettre en forme visuellement les données (tableaux, graphes...) selon différents backend appelés interpreteurs.
{kind=link}
Utilisation
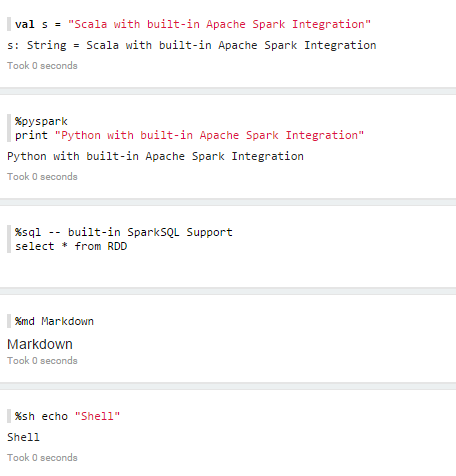
Les interpréteurs sont sous forme de plugins. Il est donc possible d'en ajouter une infinité. On peut par exemple exploiter les données venant de PostgreSQL ou d'ElasticSearch. On spécifie l'interpréteur que l'on choisit en début de ligne.
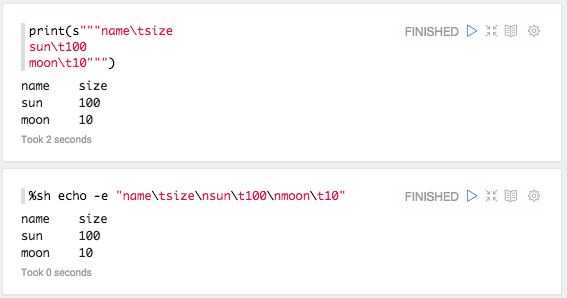
Une fois que l'on choisit son interpréteur, à partir du moment où il affiche des données pouvant être formatées dans un tableau il est possible de les mettre en forme dans un graphique. On peut aussi directement afficher des données mises en forme manuellement : https://zeppelin.incubator.apache.org/assets/themes/zeppelin/img/screenshots/display_table.png
{kind=link}
Ou bien de différents interpréteurs :
%psql.sql select * from mytable;
%elasticsearch get /index/type/id
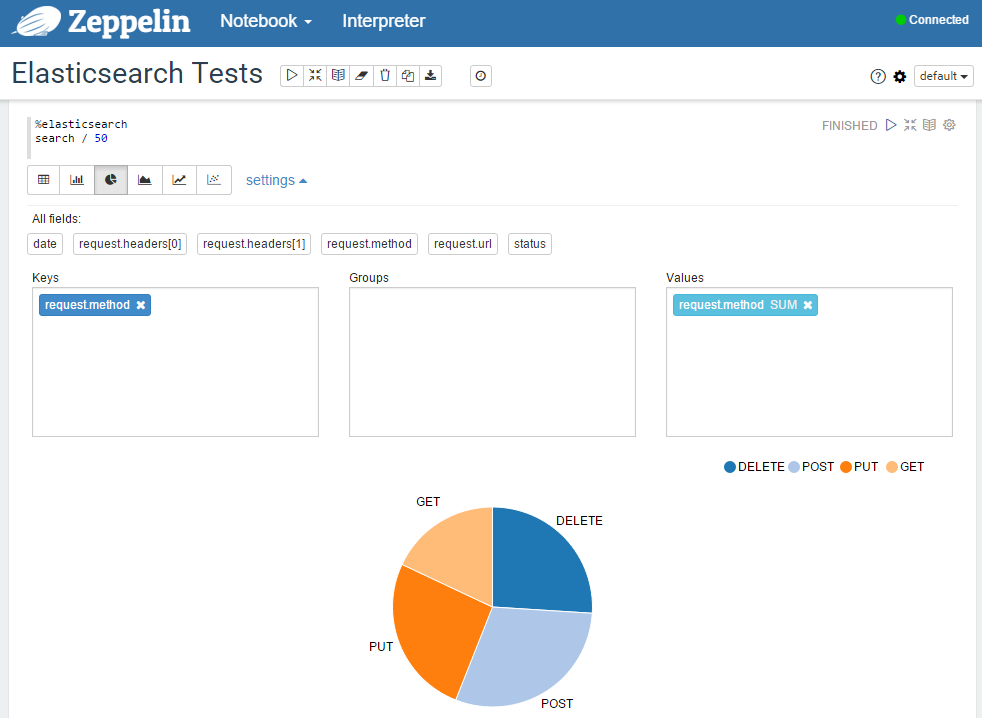
Les données peuvent ensuite être affichées de manière interactives :
{kind=link}
Zeppelin intègre directement Spark qui est un framework open source de calcul distribué directement en mémoire vive.
Il est du coup possible de faire jouer des scripts :
val bankText = sc.textFile("yourPath/bank/bank-full.csv")
case class Bank(age:Integer, job:String, marital : String, education : String, balance : Integer)
// split each line, filter out header (starts with "age"), and map it into Bank case class
val bank = bankText.map(s=>s.split(";")).filter(s=>s(0)!="\"age\"").map(
s=>Bank(s(0).toInt,
s(1).replaceAll("\"", ""),
s(2).replaceAll("\"", ""),
s(3).replaceAll("\"", ""),
s(5).replaceAll("\"", "").toInt
)
)
// convert to DataFrame and create temporal table
bank.toDF().registerTempTable("bank")
Dans ce exemple on parse le CSV pour créer des objets de type Bank.
Puis d'appliquer des requêtes dessus comme par exemple, si on veut avoir la distribution d'age d'une banque :
%sql select age, count(1) from bank where age < 30 group by age order by age
Installation
Télécharger le dernier binaire: [1]
Décompresser le tgz puis se déplacer dans le dossier.
Pour démarrer Zeppelin :
bin/zeppelin-daemon.sh start
Si tout s'est bien passé, il suffit d'ensuite visiter [2] dans le navigateur.
Pour stopper Zeppelin :
bin/zeppelin-daemon.sh stop