Difference between revisions of "PAGE WIKI ETUDIANTS 2010-11 SERRURE VOCALE"
| Line 40: | Line 40: | ||
#: |
#: |
||
#:* Contenu : une résistance (220 Ohms), un transistor NPN et l'adaptateur alimentation. |
#:* Contenu : une résistance (220 Ohms), un transistor NPN et l'adaptateur alimentation. |
||
| − | #:* Schéma : [[ |
+ | #:* Schéma : [[File:Schema.gif]] |
#:* Alimentation : est fourni avec le circuit un transformateur courant alternatif 220 - continu 9V. |
#:* Alimentation : est fourni avec le circuit un transformateur courant alternatif 220 - continu 9V. |
||
#: |
#: |
||
Revision as of 14:15, 13 March 2011
Composition du groupe gache électrique // serrure vocale :
Chefs de projet :
- Florian FAUVARQUE
- Marc VOLAINE
Membres du groupe "IHM" :
- Frédéric DUPIN
- Jonathan HARTNAGEL
- Cédric MERIADEC
- Clément RIGNAULT
Membres du groupe "ELECTRIQUE" :
- Frédéric COUDURIER
- Anthony DAMOTTE
Membres du groupe "ALGORITHMIQUE" :
- Maxime CONQ
- Raphaëlle DIDIER
- Floriane PIHUIT
Gâche électronique:
Cette partie a pour but d'expliquer et d'illustrer le fonctionnement de la gâche électronique. Des comptes-rendus et documentations supplémentaires sont disponibles en annexe.

- La gâche électrique:
- La gâche électrique provient d'un projet réalisé par les étudiants RICM5 promotion 2010 intitulé : TouchKey.
-
- Gache électrique réversible gauche ou droite.
- Dimension du corps: 160x25x30 en aluminium inoxidable donc garde le même aspect trés longtemps
- Fonctionne en 10VDC avec une tolérance importante de 20% soit entre 8 volts et 12 volts permettant toujours d'être très adaptable a de nombreuses installations.
- Température de fonctionnement: de - 15 degrée centigrade à + 50 degrée centigrade
- Le circuit électronique:
- Le circuit électronique provient également du projet TouchKey.
-
- Contenu : une résistance (220 Ohms), un transistor NPN et l'adaptateur alimentation.
- Schéma :
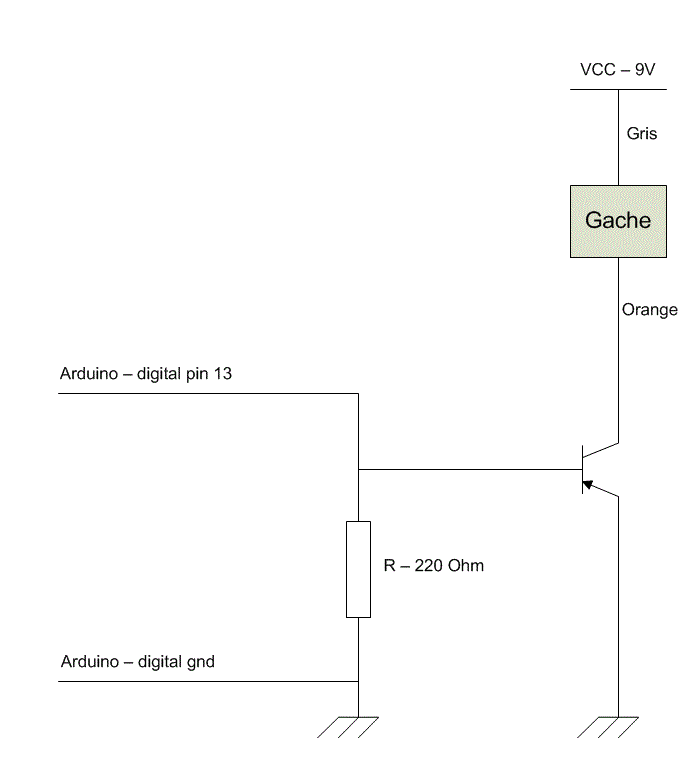
- Alimentation : est fourni avec le circuit un transformateur courant alternatif 220 - continu 9V.
- La conversion numérique/analogique (CAN)
-
- Technologies utilisées : JAVA, USB, Port série
- Sources du code :
-

Gachette electrique - Cahier des charges / Schéma du montage
Analyse de la parole:
Le but du projet est de permettre à certains locuteurs préalablement enregistrés dans le système d'ouvrir une porte simplement par la parole. C'est ici qu'entre en jeu la phase d'analyse. Avant de commencer le projet, nous avons étudié les TPs de biométrie de l'année dernière ([1]) ainsi que plusieurs compte-rendus de précédents étudiants que l'on nous a fournis. Cela nous donne toutes les étapes ainsi que la marche à suivre en ce qui concerne la reconnaissance de locuteurs. Enfin, nous avons vu dans les comptes rendus de TPs que les résultats sont meilleurs lorsque l'on normalise et que l'on détecte l'énergie des signaux, nous ferons de même pour notre projet.
Voici les différentes étapes de la reconnaissance d'un locuteur :
- Tout d'abord, nous récupérons un ensemble de voix qui nous servira à créer un modèle du monde. Nous avons utilisé les voix des membres du projet (ce qui nous donne 12 voix : 9 d'hommes et 3 de femmes). Pour cela, nous utilisons un logiciel en ligne de commande sous linux qui se nomme bplay ([2]), et la commande pour enregistrer une voix : brec -r -b 16 -s 16000 -t 60 locuteur.raw : "-b 16" pour préciser le nombre de bits, "-s 16000" pour préciser la fréquence (16kHz) et "-t 60" pour enregistrer 60 secondes de signal. A remarquer également que le fichier enregistré a une extension en .raw ; nous avons choisi cela car c'est le même format que pour les TPs. Nous pouvons également écouter le signal enregistré avec la commande : bplay -b 16 -s 16000 locuteur.raw
- --------------------------------------------------------------------------------------------------------------------------------------
- Pour la suite, il est important de suivre l'arborescence de dossiers utilisée pour le TP :
- output_files
- cfg (dossier de config) contenant l'ensemble des fichiers de configuration donnés dans le TP
- gmm (dossier des modèles)
- lbl (dossier des labels)
- lst (dossier des fichiers all.lst, world.lst (pointant juste le fichier all.lst), world.weight)
- ndx (dossier des index)
- prm (dossier des vecteurs de paramètres, normalisés ou non)
- res (dossier des résultats des tests de reconnaissance)
- LIA_RAL
- input (dossier qui contiendra les voix de tests)
- --------------------------------------------------------------------------------------------------------------------------------------
- Maintenant que nous avons enregistré ces 12 voix (extension .raw), nous allons traiter ces signaux.
- Première étape, générer les vecteurs de paramètres pour chacun des signaux.
- Pour cela, nous utilisons un outil fourni dans le TP : spro ([3]) qui propose une commande sfbcep -F PCM16 -f16000 -p 19 -e -D -A locuteur.raw locuteur.prm qui va créer un vecteur de paramètres pour le fichier locuteur.raw. Comme nous avons 12 signaux, donc 12 vecteurs à générer, nous allons créer un script csh. Pour cela, nous plaçons tout d'abord dans un fichier all.lst la liste des noms des signaux (noms des locuteurs).
- Et nous écrivons notre script :
- foreach i (`cat all.lst`)
- sfbcep -F PCM16 -f16000 -p 19 -e -D -A $i.raw $i.prm
- end
- Deuxième étape, normaliser les paramètres de chacun des signaux
- Nous utilisons une nouvelle fois un outil fourni dans le TP : "LIA_RAL" ([4]). Et nous utilisons la commande NormFeat :
- ./LIA_RAL/LIA_SpkDet/NormFeat/NormFeat.exe --config ./cfg/NormFeat_energy.cfg --inputFeatureFilename ./lst/all.lst --debug false --verbose true
- Cette commande crée les fichiers locuteur.enr.prm dans le dossier prm
- Nous utilisons une nouvelle fois un outil fourni dans le TP : "LIA_RAL" ([4]). Et nous utilisons la commande NormFeat :
- Troisième étape, détecter l'énergie de chacun des signaux
- Pour détecter cette énergie, nous allons utiliser la commande EnergyDetector :
- ./LIA_RAL/LIA_SpkDet/EnergyDetector/EnergyDetector.exe --config ./cfg/EnergyDetector.cfg --inputFeatureFilename ./lst/all.lst --verbose true --debug false
- Cette commande crée les fichiers locuteur.lbl dans le dossier lbl (labels)
- Pour détecter cette énergie, nous allons utiliser la commande EnergyDetector :
- Quatrième étape, re-normaliser les paramètres
- On utilise une nouvelle fois la commande NormFeat, mais avec un fichier de configuration différent :
- ./LIA_RAL/LIA_SpkDet/NormFeat/NormFeat.exe --config ./cfg/NormFeat.cfg --inputFeatureFilename ./lst/all.lst
- Cette commande crée les fichiers locuteur.norm.prm dans le dossier prm
- On utilise une nouvelle fois la commande NormFeat, mais avec un fichier de configuration différent :
- Cinquième étape, apprendre le modèle du monde
- Nous créons ici ce que l'on appelle le modèle du monde, c'est à dire que l'on fait une sorte de moyenne des 12 voix que nous avons préalablement enregistrées. Nous utilisons pour cela la commande TrainWorld qui se décompose en deux commandes :
- ./LIA_RAL/LIA_SpkDet/TrainWorld/TrainWorld.exe --config ./cfg/TrainWorldInit.cfg --inputStreamList ./lst/world.lst --weightStreamList ./lst/world.weight --outputWorldFilename world_init --debug false --verbose true
- ./LIA_RAL/LIA_SpkDet/TrainWorld/TrainWorld.exe --config ./cfg/TrainWorldFinal.cfg --inputStreamList ./lst/world.lst --weightStreamList ./lst/world.weight --outputWorldFilename world --inputWorldFilename world_init --debug false --verbose true
- Cela crée le fichier world.gmm dans le dossier gmm
- Nous créons ici ce que l'on appelle le modèle du monde, c'est à dire que l'on fait une sorte de moyenne des 12 voix que nous avons préalablement enregistrées. Nous utilisons pour cela la commande TrainWorld qui se décompose en deux commandes :
- Sixième étape, créer les modèles de locuteurs
- Tout d'abord, nous choisissons les locuteurs qui seront acceptés par le système. Ensuite, nous créons un fichier locuteurs.ndx dans le dossier ndx qui contiendra les noms de ces locuteurs. Cette liste est de la forme : "nom_du_fichier_raw nom_du_fichier_gmm" (exemple : "maxime maxime" pour des fichiers maxime.raw et maxime.gmm). Nous créons alors un modèle pour chacun de ces locuteurs en combinant le modèle du monde avec un fichier audio (.raw) de chacun des locuteurs (le même que celui enregistré pour créer le modèle du monde). Nous utilisons pour cela la commande TrainTarget :
- ./LIA_RAL/LIA_SpkDet/TrainTarget/TrainTarget.exe --config ./cfg/target.cfg --targetIdList ./ndx/locuteurs.ndx --inputWorldFilename world --debug false --verbose true
- Cela nous crée pour chacun des locuteurs acceptés par le sytème un fichier locuteur.gmm dans le dossier gmm.
- Tout d'abord, nous choisissons les locuteurs qui seront acceptés par le système. Ensuite, nous créons un fichier locuteurs.ndx dans le dossier ndx qui contiendra les noms de ces locuteurs. Cette liste est de la forme : "nom_du_fichier_raw nom_du_fichier_gmm" (exemple : "maxime maxime" pour des fichiers maxime.raw et maxime.gmm). Nous créons alors un modèle pour chacun de ces locuteurs en combinant le modèle du monde avec un fichier audio (.raw) de chacun des locuteurs (le même que celui enregistré pour créer le modèle du monde). Nous utilisons pour cela la commande TrainTarget :
- Une fois que sont créés ces modèles de locuteur, nous pouvons effectuer quelques tests.
- Pour cela, il suffit d'enregistrer la voix de la personne qui souhaite être identifiée, de la traiter (créer le vecteur de paramètres, normaliser, détecter l'énergie, re-normaliser) et d'appeler la commande ComputeTest :
- ./LIA_RAL/LIA_SpkDet/ComputeTest/ComputeTest.exe --config ./cfg/target_seg.cfg --ndxFilename ./ndx/locuteur.ndx --worldModelFilename world --inputWorldFilename world --outputFilename ./res/locuteurs.res --debug false --verbose true
- Cela nous enregistre dans le fichier locuteur.res un ensemble de valeurs dont le résultat final qui nous intéresse.
- Nous utilisons ici un nouveau fichier locuteur.ndx (de la même forme que le fichier locuteurs.ndx explicité précédemment) qui contient seulement le nom de la personne qui souhaite être reconnue.
- Pour cela, il suffit d'enregistrer la voix de la personne qui souhaite être identifiée, de la traiter (créer le vecteur de paramètres, normaliser, détecter l'énergie, re-normaliser) et d'appeler la commande ComputeTest :
Nous devons maintenant appliquer tout cela à notre projet. Notre système est divisé en 2 parties : acquisition et reconnaissance
- Acquisition
- La phase d'acquisition nous permet d'enregistrer la voix d'une personne jusqu'alors absente du système, de l'ajouter au modèle du monde, et, si on le souhaite, de l'ajouter aux personnes reconnues par le système. Pour cela, nous avons écrit un script shell qui enregistre un signal d'une durée définie par l'utilisateur, avec le nom qu'il souhaite lui donner ainsi que son souhait d'être accepté ou non par le système.
- #!/bin/bash
- # On se place dans le bon dossier
- cd algo/output_files
- # On vérifie que le nom entré n'est pas déjà dans la liste pour ne pas l'écraser
- if ! grep -i $1 ./lst/all.lst
- then
- # On enregistre le nouveau locuteur
- brec -r -b 16 -s 16000 -t $2 ./../input_files/$1.raw
- # On crée le vecteur de paramètre
- sfbcep -F PCM16 -f16000 -p 19 -e -D -A ./../input_files/$1.raw ./prm/$1.prm
- # On traite le signal (normalisation, détection d'énergie, re-normalisation)
- ./LIA_RAL/LIA_SpkDet/NormFeat/NormFeat.exe --config ./cfg/NormFeat_energy.cfg --inputFeatureFilename $1 --debug false --verbose true
- ./LIA_RAL/LIA_SpkDet/EnergyDetector/EnergyDetector.exe --config ./cfg/EnergyDetector.cfg --inputFeatureFilename $1 --verbose true --debug false
- ./LIA_RAL/LIA_SpkDet/NormFeat/NormFeat.exe --config ./cfg/NormFeat.cfg --inputFeatureFilename $1
- # On ajoute le nom du locuteur dans le fichier all.lst
- echo $1 >> ./lst/all.lst
- # On crée le nouveau modèle du monde
- ./LIA_RAL/LIA_SpkDet/TrainWorld/TrainWorld.exe --config ./cfg/TrainWorldInit.cfg --inputStreamList ./lst/world.lst --weightStreamList ./lst/world.weight --outputWorldFilename world_init --debug false --verbose true
- ./LIA_RAL/LIA_SpkDet/TrainWorld/TrainWorld.exe --config ./cfg/TrainWorldFinal.cfg --inputStreamList ./lst/world.lst --weightStreamList ./lst/world.weight --outputWorldFilename world --inputWorldFilename world_init --debug false --verbose true
- # On regarde si le locuteur souhaite pouvoir être reconnu par le système
- if [ $3 -ne 0 ]
- then
- # Si c'est le cas, alors on l'ajoute dans le fichier locuteurs.ndx pour que son modèle soit généré
- echo $1 $1 >> ./ndx/locuteurs.ndx
- then
- fi
- # On re-génère les modèles des locuteurs acceptés par le système avec le nouveau modèle du monde
- ./LIA_RAL/LIA_SpkDet/TrainTarget/TrainTarget.exe --config ./cfg/target.cfg --targetIdList ./ndx/locuteurs.ndx --inputWorldFilename world --debug false --verbose true
- then
- fi
- Avec :
- $1 (1er paramètre) : nom du locuteur qui s'ajoute au système
- $2 (2ème paramètre) : Durée de l'enregistrement
- $3 (3ème paramètre) : 1 si le locuteur souhaite être accepté par le système, et 0 sinon
- De plus, nous avons créé une méthode java permettant d'exécuter un script shell en lui passant les paramètres voulus.
- La phase d'acquisition nous permet d'enregistrer la voix d'une personne jusqu'alors absente du système, de l'ajouter au modèle du monde, et, si on le souhaite, de l'ajouter aux personnes reconnues par le système. Pour cela, nous avons écrit un script shell qui enregistre un signal d'une durée définie par l'utilisateur, avec le nom qu'il souhaite lui donner ainsi que son souhait d'être accepté ou non par le système.
- Reconnaissance
- C'est dans la partie reconnaissance que nous allons tester si une personne peut ouvrir la porte ou non. Pour cela, nous récupérons le nom de cette personne, nous enregistrons sa voix pendant quelques secondes, nous créons le vecteur de paramètres, le traitons (normalisation, détection d'énergie, re-normalisation) et effectuons un test avec son modèle de locuteur (s'il existe). Si le résultat est plus grand qu'un seuil (que nous pouvons fixer) alors la personne est acceptée et la porte s'ouvre, sinon, elle est refusée et la porte reste close. Là encore, nous avons écrit un script qui enregistre le locuteur pendant quelques secondes, crée le vecteur de paramètres, traite le signal (normalisation, détection de l'énergie, re-normalisation) puis teste, en fonction de son nom, si ce locuteur est reconnu par le système ou non. Enfin, nous enregistrons le résultat dans un fichier de résultat d'extension .res dans le dossier res et récupérons seulement la valeur qui nous intéresse dans un fichier nommé result (lui aussi dans le dossier res).
- #!/bin/bash
- # On se place dans le bon dossier
- cd algo/output_files/
- # On enregistre le locuteur qui souhaite être reconnu
- brec -r -b 16 -s 16000 -t 3 ./input/$1.raw
- # On crée le vecteur de paramètre
- sfbcep -F PCM16 -f16000 -p 19 -e -D -A ./input/$1.raw ./prm/$1.prm
- # On traite le signal (normalisation, détection d'énergie, re-normalisation)
- ./LIA_RAL/LIA_SpkDet/NormFeat/NormFeat.exe --config ./cfg/NormFeat_energy.cfg --inputFeatureFilename $1 --debug false --verbose true
- ./LIA_RAL/LIA_SpkDet/EnergyDetector/EnergyDetector.exe --config ./cfg/EnergyDetector.cfg --inputFeatureFilename $1 --verbose true --debug false
- ./LIA_RAL/LIA_SpkDet/NormFeat/NormFeat.exe --config ./cfg/NormFeat.cfg --inputFeatureFilename $1
- # On effectue un test de reconnaissance sur le locuteur
- ./LIA_RAL/LIA_SpkDet/ComputeTest/ComputeTest.exe --config ./cfg/target_seg.cfg --ndxFilename ./ndx/$1.ndx --worldModelFilename world --inputWorldFilename world --outputFilename ./res/$1.res --debug false --verbose true
- # On place la valeur qui nous intéresse dans le fichier result
- awk '{print $NF}' ./res/$1.res > ./res/result
- Avec :
- $1 (1er paramètre) : nom du locuteur qui effectue le test de reconnaissance
- Il ne nous reste plus qu'à lire ce fichier result en java, de comparer la valeur que nous trouvons avec le seuil fixé préalablement par l'utilisateur et d'ouvrir ou non la porte en fonction de ce résultat.
- C'est dans la partie reconnaissance que nous allons tester si une personne peut ouvrir la porte ou non. Pour cela, nous récupérons le nom de cette personne, nous enregistrons sa voix pendant quelques secondes, nous créons le vecteur de paramètres, le traitons (normalisation, détection d'énergie, re-normalisation) et effectuons un test avec son modèle de locuteur (s'il existe). Si le résultat est plus grand qu'un seuil (que nous pouvons fixer) alors la personne est acceptée et la porte s'ouvre, sinon, elle est refusée et la porte reste close. Là encore, nous avons écrit un script qui enregistre le locuteur pendant quelques secondes, crée le vecteur de paramètres, traite le signal (normalisation, détection de l'énergie, re-normalisation) puis teste, en fonction de son nom, si ce locuteur est reconnu par le système ou non. Enfin, nous enregistrons le résultat dans un fichier de résultat d'extension .res dans le dossier res et récupérons seulement la valeur qui nous intéresse dans un fichier nommé result (lui aussi dans le dossier res).
Interface Graphique
Consultez la page dédiée ci dessous
Interface graphique du client - Cahier des charges / Esquisses de l'IHM